
R을 이용한 한글 텍스트 마이닝 다섯 번째 포스팅은 TDM, cast_tdm 함수를 이용한 단어 문서 행렬의 구성 방법에 관한 R 실습 코드와 설명입니다. 마지막에 단어 문서 행렬 구성 후, qgraph 패키지를 이용한 동시출현네트워크분석(co-occurrence network anlysis)까지 설명하고 마무리하겠습니다. 실습할 데이터는 계속 이어서 네이버 큐 보도자료입니다. 해당 데이터는 두번째 포스팅에 올려두었으니, 참고 바랍니다. 또한 아래 포스팅을 참고하여 KoNLP 패키지 먼저 설치해야 R을 이용한 한글 텍스트 마이닝 분석이 가능합니다.
R 한글 텍스트 마이닝 분석 (4) : tidygraph와 ggraph │키워드 네트워크 분석
R을 이용한 한글 텍스트 마이닝 분석 다섯 번째 포스팅 주제는 tidygraph와 ggraph를 이용한 키워드 네트워크 분석입니다. 이전에 활용한 네이버의 생성형 AI 서비스 큐 보도자료를 계속 인용하겠습
e-datanews.tistory.com
Gephi 사용법│의미망 모형│코사인 유사도│논문작성프로그램
Gephi 사용법│의미망 모형│코사인 유사도│논문작성프로그램 텍스트마이닝 분석방법 중 흔희 의미망 분석을 구현하는 방법은 여러 가지가 있으며, 이 블로그에서도 igraph패키지라든가 sna패키
e-datanews.tistory.com
1. 패키지 로딩
라이브러리 함수를 이용하여 분석에 필요한 패키지를 로딩합니다. 해당 패키지 설치가 안되어 있는 경우 install.packages함수를 이용하여 분석에 필요한 패키지를 먼저 설치해야 합니다.
R 코드
library(tidyverse)
library(tidytext)
library(KoNLP)
useNIADic()
library(readxl)
2. 분석 폴더 지정
분석 데이터의 호출이나 저장을 위한 폴더를 지정합니다. 지정하지 않은 경우 내 문서 폴더가 작업 분석 폴더로 자동 지정 됩니다. 포스팅에서는 계속 이어서 C 드라이브 밑에 test폴더 밑에 ko_test라는 폴더를 생성하고, 해당 폴더를 작업용 분석 폴더로 지정합니다.
R 코드
setwd("C:/test/ko_test")
3. 데이터 호출
분석할 데이터를 호출합니다. 분석 데이터 파일 형식은 엑셀이며, read_excel 이라는 함수를 이용하여 데이터를 호출합니다.
R 코드
naverq <- read_excel("naverq.xlsx", col_names = TRUE)
4. 전처리 및 토큰화
데이터 중 한글 데이터만 추출하며, 각 행을 id로 부여합니다. 해당 id는 각각 하나의 문서가 됩니다.
R 코드
naverq_keywords <- naverq %>%
select(keyword) %>%
mutate(keyword = str_replace_all(keyword, "[^가-힣]", " "),
keyword = str_squish(keyword),
id = row_number())
R 코드
keywords_pos <- naverq_keywords %>%
unnest_tokens(input = keyword,
output = word,
token = SimplePos22,
drop = F)
5. 품사분석
키워드에서 SimplePos22 함수를 이용하여 명사, 동사 및 형용사를 추출하기 위한 품사분석을 각각 실행한 후, 2 문자 이상의 단어들만 추출한 후, 하나의 열로 합칩니다.
R 코드
keywords_pos %>%
select(word, keyword)
keywords_pos <- keywords_pos %>%
separate_rows(word, sep = "[+]")
keywords_pos %>%
select(word, keyword)
#명사
noun <- keywords_pos %>%
filter(str_detect(word, "/n")) %>%
mutate(word = str_remove(word, "/.*$"))
noun %>%
select(word, keyword)
noun %>%
count(word, sort = T)
#동사와 형용사
pvpa <- keywords_pos %>%
filter(str_detect(word, "/pv|/pa")) %>%
mutate(word = str_replace(word, "/.*$", "다"))
pvpa %>%
select(word, keyword)
pvpa %>%
count(word, sort = T)
# 품사(명사, 동사와 형용사) 결합
kw_noun_pvpa <- bind_rows(noun, pvpa) %>%
filter(str_count(word) >= 2) %>%
arrange(id)
kw_noun_pvpa %>%
select(word, keyword)
kw_noun_pvpa_new <- kw_noun_pvpa %>%
separate_rows(word, sep = "[+]") %>%
filter(str_detect(word, "/n|/pv|/pa")) %>%
mutate(word = ifelse(str_detect(word, "/pv|/pa"),
str_replace(word, "/.*$", "다"),
str_remove(word, "/.*$"))) %>%
filter(str_count(word) >= 2) %>%
arrange(id)
6. 불용어 등 추가 데이터 정제
네이버 라는 단어는 추가 불용어 처리하며, gsub 함수를 이용하여 단계별이라는 단어는 "단계"라는 단어 추가 정제합니다.
R 코드
stopwords <- tibble(word = c("네이버"))
kw_noun_pvpa <- kw_noun_pvpa %>%
mutate(word = gsub("단계별", "단계", word)) %>%
anti_join(stopwords, by = "word")
kw_noun_pvpa
7. 단어-문서 행렬 (Term-Document Matrix, TDM)
cast_tdm 함수를 이용하여 단어 문서 행렬을 구성합니다.
R 코드
tdm <- kw_noun_pvpa %>%
count(id, word) %>%
cast_tdm(document = id, term = word, value = n)
tdm
<<TermDocumentMatrix (terms: 91, documents: 25)>>
Non-/sparse entries: 186/2089
Sparsity : 92%
Maximal term length: 6
Weighting : term frequency (tf)
위의 결과는 다음과 같이 해석할 수 있습니다.
생성된 문서-용어 행렬은 91 × 25의 크기를 가지며, 2,275개(=186 + 2089)의 셀 가운데 2,089개(=2,275-186)의 셀은 0의 값을 가집니다. 또한 셀의 92% [=2,089개/(186 + 2089)]가 0으로 채워졌다는 것을 의미하며, 가장 긴 단어는 6자로 이루어져 있고, Weighting은 단어 빈도 기준(term frequency) 임을 각각 의미합니다.
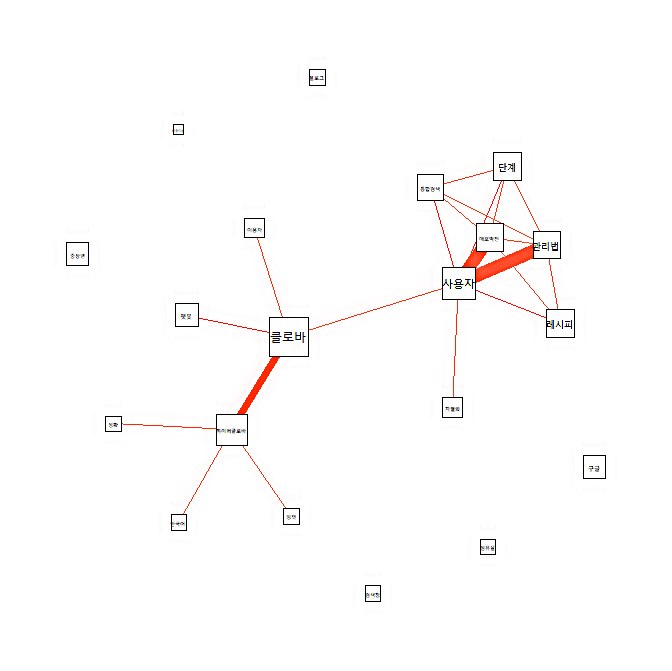
8. 동시출현네트워크분석(co-occurrence network anlysis)
앞에서 구성한 단어 문서 행렬을 이용하여 동시출현네트워크분석(co-occurrence network anlysis)을 시도하겠습니다. 이용할 패키지는 qgraph입니다.
R 코드
library(qgraph)
q.g <- as.matrix(tdm)
word.count <- rowSums(q.g)
word.order <- order(word.count, decreasing=TRUE)
freq.words <- q.g [word.order [1:20], ]
co.matrix <- freq.words %*% t(freq.words)
qgraph(co.matrix, labels=rownames(co.matrix), diag=FALSE, layout='spring', shape = "square", threshold=3, edge.color='tomato', vsize=log(diag(co.matrix)) * 2)
텍스트 마이닝 │한글 │R 4.3.1│Window 11 기준
R을 이용한 한글 텍스트 마이닝(R 4.3.1과 윈도 11 기준) 포스팅이 계속 업데이트되고 있습니다. 관심 있는 분들은 KoNLP 설치 오류 해결 후, 다음 포스팅 순서에 따라 실습해 보기 바랍니다. 키워드
e-datanews.tistory.com
유사도 지수 차이 비교 │ Jaccard │Dice│ Simpson 계수 │KH Coder3 동시출현네트워크분석
KH Coder3가 제공하는 유사도 지수 계산 방법은 자카드(Jaccard), 다이스(Dice), 심슨(Simpson) 지수, 코사인(Cosine), 유클리디안 (Euclidean)이 있습니다. 이들 유사도 지수 계측 방법은 KH Coder3가 제공하는 텍
e-datanews.tistory.com
9. 정리
문서 단어 행렬을 구성한 후에는 igraph 패키지를 이용하여 다양한 텍스트 네트워크 분석을 시도할 수 있습니다 다만, 중요한 점은 사전에 텍스트 데이터를 얼마나 정제하느냐입니다. 텍스트 네트워크 분석 결과는 위에서 제시한 "R" 코드대로만 구현한다면, 해당 결과를 구할 수 있겠으나, 원하는 시사점을 도출하기 위해서는 얼마나 정제된 데이터가 투입되느냐이며, 다시 한번 강조합니다만, 매우 중요합니다. 그럼 이번 포스팅은 여기서 마무리하겠습니다. 수고하셨습니다.
'교육' 카테고리의 다른 글
| 스티커 프롬프트 생성기와 뤼튼을 이용한 노트북 텀블러 스티커 자동 제작 (0) | 2023.11.24 |
|---|---|
| 빗썸 관심도 변화 │구글 레이싱 라인 그래프 암호화폐(BTC ETH XRP LUNA) │Flourish (0) | 2023.11.14 |
| 무료 일본어 AI 자동 텍스트 마이닝 사이트 사용법 (2) │아마존 재팬 고객 리뷰 분석 │User Local(ユーザーローカル) (0) | 2023.10.17 |
| AI 자동 무료 텍스트 마이닝 일본어 사이트 사용법 (1)│ユーザーローカル (0) | 2023.10.16 |
| R 한글 텍스트 마이닝 분석 (4) : tidygraph와 ggraph │키워드 네트워크 분석 (0) | 2023.10.10 |



