
R을 이용한 한글 텍스트 마이닝 분석 다섯 번째 포스팅 주제는 tidygraph와 ggraph를 이용한 키워드 네트워크 분석입니다. 이전에 활용한 네이버의 생성형 AI 서비스 큐 보도자료를 계속 인용하겠습니다. 실습할 R 코드는 포스팅 하단에 올려두었습니다.
R 한글 텍스트 마이닝 (3) : TF - IDF
R을 이용한 한글 텍스트 마이닝 세 번째 포스팅은 TF-IDF입니다. TF-IDF 개념은 이전 포스팅에서도 많이 언급했습니다. 주요 개념은 다음 포스팅 등을 참고하기 바랍니다. 단어 빈도-역문서 빈도 분
e-datanews.tistory.com
1. 패지키 로딩, 작업 폴더 지정, 엑셀 데이터 호출 및 데이터 전처리
분석에 필요한 R 패지키 로드, `setwd` 함수를 이용한 작업 폴더 지정("C:/test/ko_test"), `read_excel` 함수를 이용한 "naverq.xlsx" 파일 호출 그리고 특정 칼럼(`keyword`)을 선택한 후, 한글 이외의 문자를 제거하고 단어를 추출하고 명사와 동사/형용사를 분리하는 작업까지는 이전 포스팅 내용과 동일합니다.
2. 단어 쌍과 그래프 생성
단어들 간의 관계를 파악하기 위하여 전처리된 데이터에서 단어 쌍을 생성한 후, 단어들 간의 관계를 시각화하기 위하여 단어 쌍을 기반으로 한 그래프를 생성합니다.
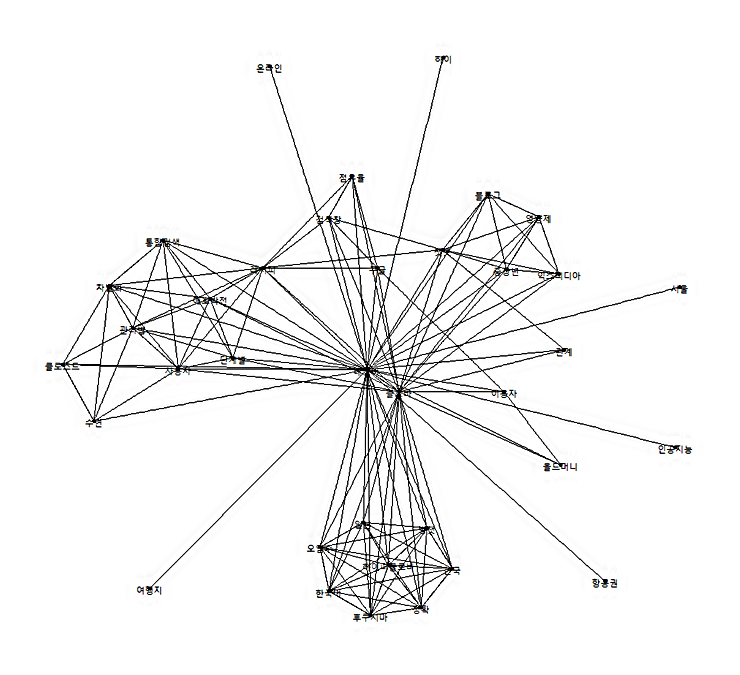
3. 키워드 네트워크 시각화 함수 정의 및 시각화 구현
키워드 네트워크를 시각화하기 위한 사용자 함수를 먼저 정의합니다. 이렇게 사전에 지정된 형식에 따라 그래프가 구현됩니다.
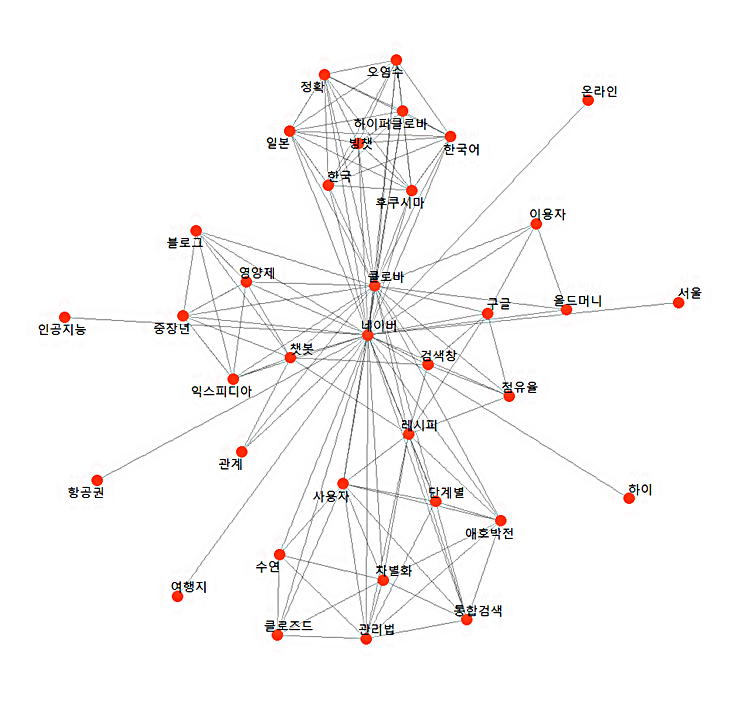
4. 키워드 연결중심성과 군집 분석
단어들의 연결중심성을 계산하고, 군집별로 그 결과를 시각화합니다. ggraph 옵션에서 노드(단어)들을 어떻게 배치할 것인지를 결정하는 레이아웃 변경("fr", "kk", "lgl" 등)을 통해 각 노드(단어)들을 정렬할 수 있습니다. 특히 ggraph의 repel 옵션을 사용하여 레이아웃 최적화와 노드들의 겹침 현상을 피할 수 있습니다.
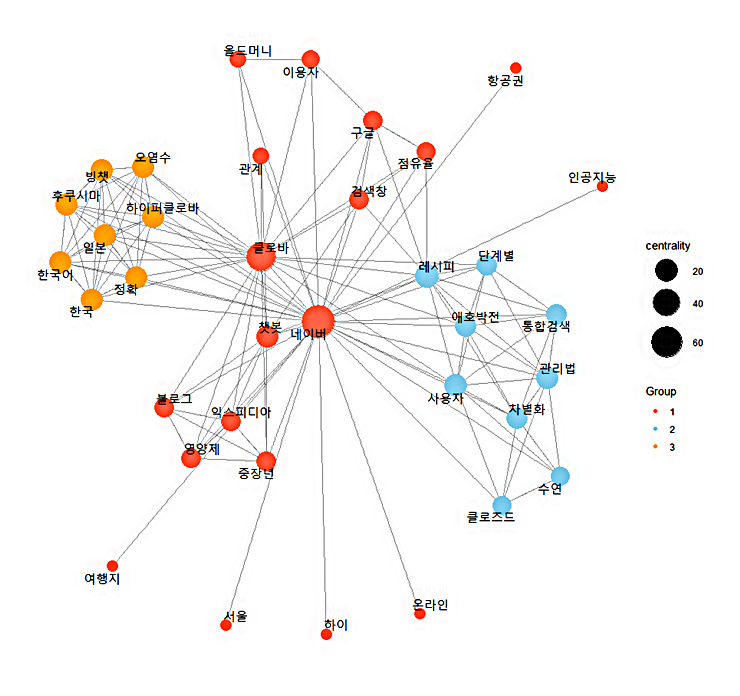
5. 분석 결과 저장
분석 결과를 "graph_kw.xlsx" 파일에 저장합니다. 해당 파일은 사전에 지정한 작업 폴더에 저장됩니다. 위 순서대로 R 실행코드가 다음 메모장 파일에 있습니다. 각자 내려 받고 실습하면 되겠습니다.
6. 파일 다운로드
이번 포스팅에서 설명한 R 실습 파일을 아래와 같이 업로드해두겠습니다. 참고 바랍니다.
'교육' 카테고리의 다른 글
| 무료 일본어 AI 자동 텍스트 마이닝 사이트 사용법 (2) │아마존 재팬 고객 리뷰 분석 │User Local(ユーザーローカル) (0) | 2023.10.17 |
|---|---|
| AI 자동 무료 텍스트 마이닝 일본어 사이트 사용법 (1)│ユーザーローカル (0) | 2023.10.16 |
| R 한글 텍스트 마이닝 (3) : TF - IDF (0) | 2023.10.03 |
| R 한글 텍스트 마이닝 분석 (2) │품사 분석과 불용어 추가 전처리 (0) | 2023.10.01 |
| R 한글 텍스트 마이닝 (1) │네이버 생성형 AI 큐 국내 보도자료 분석│엑셀 데이터 호출 및 빈도분석 시각화 (0) | 2023.09.24 |



