
논문 작성 방법 중의 하나로 많이 사용되는 한글 키워드 네트워크 분석 방법에 관하여 정리합니다. 예제 키워드는 인플루언서이며, 해당 키워드를 이용하여 국내 연구를 정리해보겠습니다. 분석도구는 지난 일본어 텍스트 마이닝에 이어 이번에도 KHcoder를 사용하며 코딩하지 않고 한글 텍스트 마이닝을 진행해보겠습니다.
KHCoder 업데이트 공지 │서비스 유료화 │2024년 2월 28일 기준
KHCoder를 한동안 사용하질 않아서 모르고 있었습니다만, 오늘 우연히 확인할 일이 있어서 웹사이트를 방문하고 나서야 최근 서비스 유료화 공지 내용을 확인할 수 있었습니다. 2024년 2월 28일을
e-datanews.tistory.com
텍스트 마이닝 토픽분석 키워드 네트워크 분석 │국내 연구 동향 │2002년-2022년
한국 학술지 인용 색인에서 텍스트 마이닝, 토픽분석 및 키워드 네트워크 분석 이라는 검색 결과를 활용하여 국내 텍스트 마이닝 관련 연구 동향을 정리해 보았습니다. 국내 텍스트 마이닝 연구
e-datanews.tistory.com
1. 학술지 키워드 수집
학술지 키워드 관련 국내 연구 동향을 검토하기 위해서는 우선 관련 학술지 정보를 수집해야 합니다. 현재 제일 많이 인용되는 학술지 DB는 한국 연구재단의 한국 학술지 인용색인입니다. 이번 포스팅 예제 키워드인 인플루언서를 키워드 검색창에 입력하면, 현재까지 총 251개의 논문을 찾을 수 있습니다. 해당 논문의 주요 정보를 엑셀 형식으로 내려받기 위해서는 회원가입 후, 로그인해야 가능합니다.
R 한글 텍스트 마이닝 (1) │네이버 생성형 AI 큐 국내 보도자료 분석│엑셀 데이터 호출 및 빈도
지난 포스팅에서 한글 텍스트 마이닝 분석을 위한 KoNLP 설치하는 방법까지 설명하였습니다. 이어서 테스트도 할 겸 엑셀의 텍스트 데이터를 호출하고, 빈도 분석까지 간단히 정리해 보겠습니다.
e-datanews.tistory.com
2. 텍스트 데이터의 구성
지난 포스팅에서 설명한 바와 같이 KHcoder에서 불러올 수 있도록 엑셀 형식을 구성합니다. 이번 활용 예제에서는 국문 키워드, 발행 연도, 인용 횟수를 수집 및 정렬하여 텍스트 마이닝을 실행하였습니다. 참고로 분석에 사용한 엑셀 파일은 아래와 같으니, 참고 바랍니다.
R 한글 텍스트 마이닝 분석 (2) │품사 분석과 불용어 추가 전처리
이번 포스팅은 SimplePos09 함수를 이용하여 명사를 추출하고, 추가적인 불용어 처리 방법을 정리합니다. 분석에 활용할 텍스트 데이터 지난 포스팅에서 사용했던 네이버의 생성형 AI 서비스 큐에
e-datanews.tistory.com
3. 데이터 호출
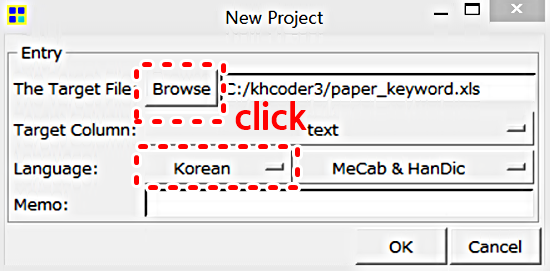
각 논문의 키워드를 추출하여 인플루언서 국내 연구 동향에 관한 키워드 네트워크를 분석합니다. 이를 위해서 사전에 준비한 한글 텍스트 데이터를 KHcoder로 호출해야 합니다. 데이터 호출은 아래 그림처럼 New 버튼을 클릭하고, 한글로 세팅한 후에 Browse를 눌러 한글 텍스트 데이터를 호출합니다.
R 한글 텍스트 마이닝 (3) : TF - IDF
R을 이용한 한글 텍스트 마이닝 세 번째 포스팅은 TF-IDF입니다. TF-IDF 개념은 이전 포스팅에서도 많이 언급했습니다. 주요 개념은 다음 포스팅 등을 참고하기 바랍니다. 단어 빈도-역문서 빈도 분
e-datanews.tistory.com
4. 분석 준비
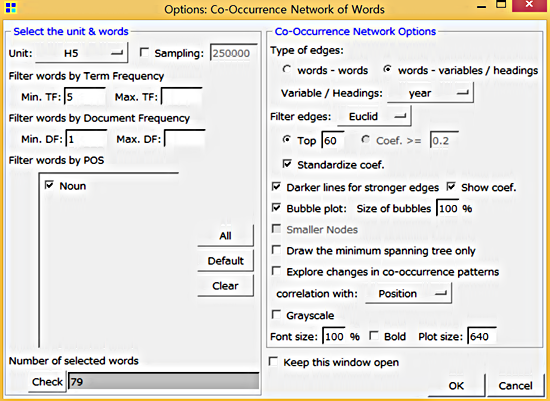
이번 포스팅에서도 동시 출현 네트워크를 통해 키워드 네트워크를 구성해보겠습니다. 아래 그림처럼 각 옵션 값을 분석 전에 설정합니다.
R 한글 텍스트 마이닝 분석 (4) : tidygraph와 ggraph │키워드 네트워크 분석
R을 이용한 한글 텍스트 마이닝 분석 다섯 번째 포스팅 주제는 tidygraph와 ggraph를 이용한 키워드 네트워크 분석입니다. 이전에 활용한 네이버의 생성형 AI 서비스 큐 보도자료를 계속 인용하겠습
e-datanews.tistory.com
5. 분석 결과
분석 결과는 아래와 같습니다. 각 해당 연도 별로 각각의 키워드가 잘 도출되고 있음을 확인할 수 있습니다. 다만, 추가적인 복합어 구성 및 불용어 처리가 필요해 보입니다.

텍스트 마이닝 사이트│웹페이지 데이터 추출 │워드클라우드 자동 생성과 토픽 모델링 분석
Auto Textmining 무료 도구인 voyant-tools를 활용한 웹페이지 데이터 추출과 이를 활용한 워드클라우드, 토픽 모델링 분석 방법을 정리합니다. Auto Textmining Free│2개 이상의 PDF 문서 텍스트 추출│네트
e-datanews.tistory.com
6. 실습 영상
아래 영상은 지금까지 설명한 내용들을 실습하는 영상이니 참고하기 바랍니다.
7. R 한글 텍스트 마이닝 : KoNLP 단계별 설치 순서와 테스트
2023년 9월 현재 R의 가장 최근 버전인 4.3.1 기준 한글 텍스트 마이닝 분석을 위한 KoNLP 설치 순서와 테스트 포스팅이 업데이트 되었습니다. 관심있는 분들은 다음 포스팅도 같이 참고하기 바랍니다.
R 한글 텍스트 마이닝 │네이버 생성형 AI 큐 국내 보도자료 분석│엑셀 데이터 호출 및 빈도분석
지난 포스팅에서 한글 텍스트 마이닝 분석을 위한 KoNLP 설치하는 방법까지 설명하였습니다. 이어서 테스트도 할 겸 엑셀의 텍스트 데이터를 호출하고, 빈도 분석까지 간단히 정리해 보겠습니다.
e-datanews.tistory.com
8. 정리
이번 포스팅에서 따로 설명하지는 않았습니다만, KHcoder 메인화면의 상단 메뉴에서 pre-processing을 누르면, Select word to analyze라는 서브메뉴가 있습니다. 해당 메뉴를 누르면, n-그램과 같은 복합어 구성과 추가적인 불용어 처리가 가능하니, 참고하기 바랍니다.
유사도 지수 차이 비교 │ Jaccard │Dice│ Simpson 계수 │KH Coder3 동시출현네트워크분석
KH Coder3가 제공하는 유사도 지수 계산 방법은 자카드(Jaccard), 다이스(Dice), 심슨(Simpson) 지수, 코사인(Cosine), 유클리디안 (Euclidean)이 있습니다. 이들 유사도 지수 계측 방법은 KH Coder3가 제공하는 텍
e-datanews.tistory.com
그 외 KH Coder3에서 제공하는 자카드 등 유사도 지수에 대한 설명은 위의 링크 포스팅을 참고하기 바랍니다.
'교육' 카테고리의 다른 글
| R ggmap 활용을 위한 구글맵 API 키 발급 방법 (0) | 2022.05.26 |
|---|---|
| 2022 추천 네일 Nail 인스타그램 일본 기업 계정 5선 │insta-lab (0) | 2022.05.25 |
| 한국 화장품 일본 소비자 리뷰 No Coding 무료 텍스트마이닝│코딩하지 않고 동시 출현 네트워크 분석│KHcoder │韓国 コスメ Yahooショッピングレビューの共起語を探す (0) | 2022.05.23 |
| 뉴욕타임즈 API 활용법 │R 텍스트마이닝 (0) | 2022.05.18 |
| 네이버 블로그 R 텍스트마이닝 │20대 여친 여사친 선물 추천 비교│네이버 오픈 API 활용 (0) | 2022.05.18 |



