
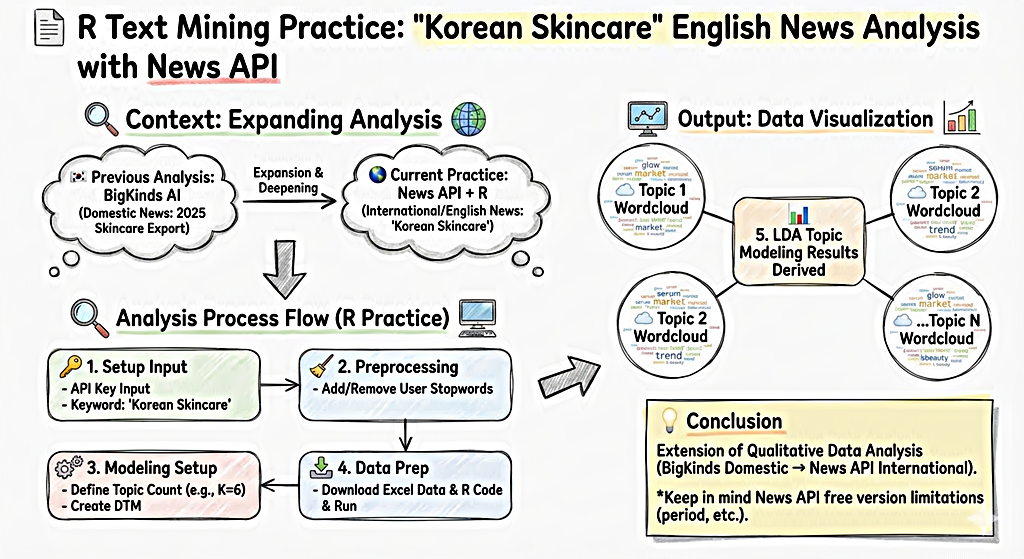
지난 포스팅에서는 빅카인즈 AI를 이용하여 "2025년 스킨케어 수출"이라는 뉴스 데이터를 수집한 후, 2025년 한국의 스킨케어 수출 주요 이슈를 정리했었는데요. 이번에는 News API에서 "Korean Skincare" 영어 뉴스 데이터를 수집한 후, R 텍스트마이닝 분석 실습을 진행하겠습니다. News API를 이용한 영어 뉴스 데이터 수집 방법은 이전 포스팅을 참고하시기 바랍니다. 이번 실습에 필요한 영어 뉴스데이터 엑셀 파일과 R 코드도 포스팅 하단에 업로드해두겠습니다. 이번 포스팅은 아래 스케치 노트 이미지와 같은 순서로 진행합니다.
정성적 데이터 분석 사례 │뉴스 데이터 분석 │2025 스킨케어 수출 키워드 분석│빅카인즈 AI
e-datanews.tistory.com
국제 뉴스 데이터 수집과 분석│News API in R
이번 포스팅에서는 News API( https://newsapi.org/ )를 통해 국제 뉴스 데이터를 수집하기 위한 R 스크립트를 공유하고, 기초적인 텍스트 마이닝 분석을 통해 빈도수 기준 핵심 키워드를 도출하는 실습
e-datanews.tistory.com
1. API Key와 키워드 입력
이전 포스팅에서 상세히 설명한 바와 같이 News API에 "Sign up"을 하면, API 키가 자동 발급됩니다. 발급된 API 키를 다음 그림의 ①과 같이 "your key"에 입력한 후, ②와 같이 검색하고 싶은 키워드를 입력합니다.

2. 불용어 추가 처리 방법
사용자가 정의하는 불용어를 분석에서 추가로 제외하기 위해서는 아래 그림의 ③과 같이 이미 불용어로 입력된 단어들에 이어서 추가 입력도 가능합니다.

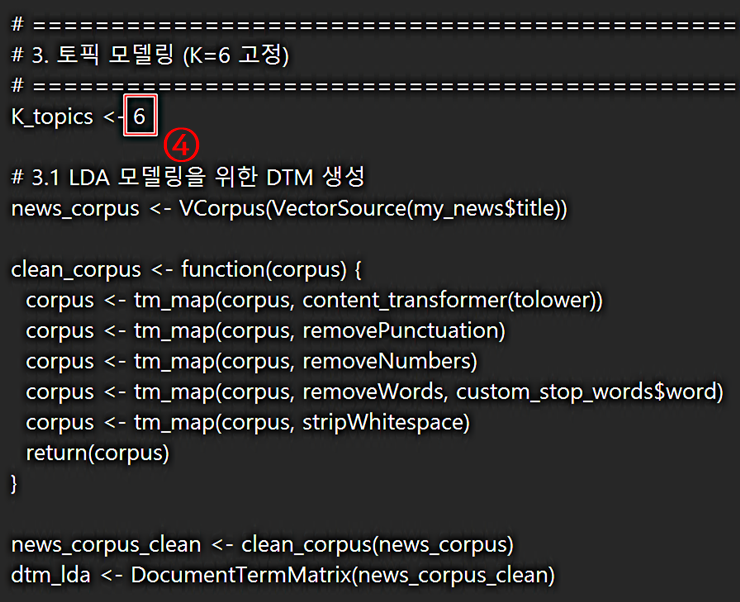
3. 토픽 수의 지정과 DTM 생성
다음 그림의 # 3. 토픽 모델링(K=6 고정)에서 토픽 수는 ④와 같이 "6"개로 결정했습니다만, 토픽 수 역시 이용자가 수정하여 사용할 수 있으니 참고하시기 바랍니다.
4. 다운로드
앞서 설명한 바와 같이 News API에서 "Korean Skincare"라는 키워드로 영어 뉴스 데이터를 수집 및 저장한 결과는 아래 엑셀 파일입니다. 또한 해당 엑셀 파일에서 "title" 열의 텍스트 데이터를 이용한 텍스트마이닝 R 코드는 아래 메모장 파일입니다. 각 파일은 내려받은 후, 실습을 진행합니다.
5. R을 이용한 LDA 토픽모델링 분석 및 데이터 시각화 결과
아래 그림은 앞서 설명한 "Korean Skincare" 뉴스 데이터의 "title" 열을 이용한 텍스트마이닝 결과입니다. 맨 마지막 R코드가 구현되면, 아래 그림처럼 각 토픽 별 상위 키워드를 이용한 워드클라우드가 생성됩니다.

6. 마무리
이번 포스팅은 지난 정성적 데이터 분석의 확장판 이라고 할 수 있습니다. 즉 지난 포스팅에서는 정성적 데이터 분석 사례로서 국내 뉴스 빅데이터 서비스인 빅카인즈 AI를 이용한 분석 방법을 정리했다면, 이번 포스팅에서는 국제 뉴스를 수집하고, R을 이용한 분석 방법까지 소개 및 정리해보았습니다. 빅카인즈 AI에 비해 News API는 수집 기간의 제한 등 무료 사용의 경우 한계점도 있으이 처음 사용하는 분들은 유념하시기 바랍니다.
'정보' 카테고리의 다른 글
| [ 무료 ] 스케치노트 제작 방법 │구글 제미나이 활용법 (0) | 2026.01.21 |
|---|---|
| 야후재팬 쇼핑 구매후기 기반의 4P 마케팅 믹스 개선 계획 실습 (0) | 2026.01.20 |
| Gemini를 이용한 대시보드 만들기 실습 │스킨케어 수출 통계 데이터 분석 (0) | 2026.01.18 |
| AI 인플루언서 제작 실습 │그록 AI와 캐럿 AI 활용 방법 (0) | 2026.01.17 |
| 리뷰 분석 기반의 인스타툰 제작 실습 │일본 해외 전시회 참가 실습 준비 (0) | 2026.01.16 |


