
지난 포스팅에서 1살, 2살 유아 장난감 선물 아마존 추천 사례를 살펴보았습니다. 이번 포스팅에서는 2살 유아 아마존 장난감 선물 중 하나를 골라 텍스트 마이닝을 활용하여 미국 소비자들의 구매후기 분석 방법을 같이 공부해보겠습니다.
1단계 : 2살 장난감 선물 아마존 고객 구매후기 자동수집
지난 포스팅부터 parsehub를 활용하여 아마존 고객 구매후기를 자동수집하는 웹스크랩핑 혹은 웹크롤링을 진행했습니다. 아직 못 본 분들은 지난 포스팅들을 참고하여 2살 아기 아마존 추천 장난감 선물 중 하나를 고른 후, 해당 구매후기 자동수집을 진행해 주기 바랍니다.
이번 포스팅에서는 예시로 첫번째 추천 상품인 Eyelike Stickers의 고객 구매 후기 중 평점 1점인 구매 후기만 자동 수집하였습니다. 아래 그림은 parsehub를 이용하여 평점 1점 구매후기만 자동 수집한 CSV 파일입니다.
2단계 : R로 텍스트 데이터 불러오기
CSV 파일로 저장된 데이터를 R로 불러드립니다. 구매후기를 텍스트 마이닝 할 예정이므로 아래와 같이 CSV 파일 변수중 구매 후기 셀의 변수 명인 name_review 지정하여 말뭉치로 저장합니다.
corpus.bracelet <- VCorpus(VectorSource(bracelet$name_review))
3단계 : 데이터 시각화
데이터 시각화 이전에 텍스트 데이터 정제 작업을 진행하고, 단어-문서 행렬을 만들어줍니다. 단어-문서 행렬까지 만들면 데이터 시각화 등등 분석하는 일만 남았습니다. 여러 번 강조했습니다만, 단어-문서 행렬 구성 이전에 데이터 정제 작업이 매우 중요하고, 시간이 오래 소요됩니다. 아래 그림들은 5회 이상 빈도 단어들을 이용한 막대그래프와 워드 클라우드입니다. 이후 의미망 분석이라든가 토픽 분석도 진행해 보기 바랍니다.
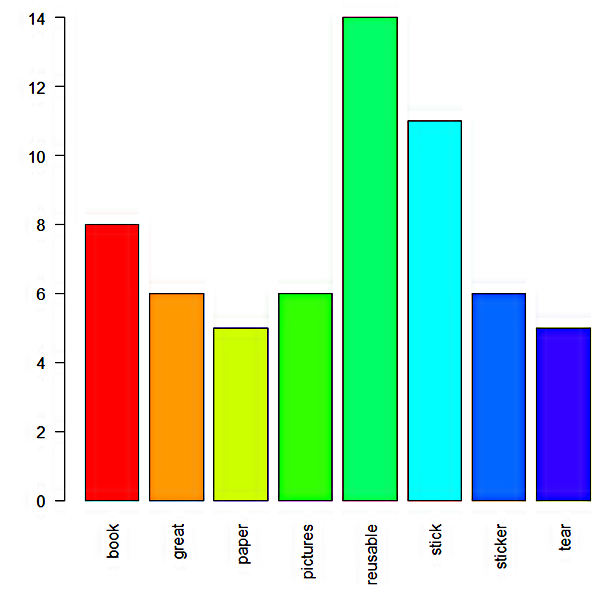

최근 parsehub 무료 이용을 통한 데이터 자동수집이 다소 원활하지 않은 것 같습니다만, 추출할 데이터를 정확히 지정했다면, 데이터 자동 수집 후, parsehub 회원가입 시, 사용했던 메일로 텍스트 데이터 자동수집을 알려줍니다. 참고하기 바랍니다. 마지막으로 R 실행코드 올려놓겠습니다. 다운로드한 후, 실행해 보기 바랍니다.
'교육' 카테고리의 다른 글
| 귀멸의 칼날 : 무한열차편 │감성분석 │네이버 영화 │R 텍스트 마이닝 (0) | 2021.05.28 |
|---|---|
| 아마존 구매후기 분석 │사회 연결망 분석 │중심성 │2살 아기 장난감 선물 (0) | 2021.05.27 |
| KoNLP 설치 순서 │2023년 9월 업데이트 │scala-library-2.11.8.jar 오류 해결 방법 │R 4.3.1 (Window 11 기준) (0) | 2021.05.21 |
| 무료 전자책 배포 │이커머스, 파괴적 혁신 진화하다 (0) | 2020.12.11 |
| 미국 기초 화장품 주요 수입국 데이터 시각화 │ ggraph (0) | 2020.12.06 |



